Googleが2026年6月10日、新しいオープンモデル「DiffusionGemma」を公開しました。従来の大規模言語モデルがテキストを1トークンずつ順番に生成するのに対し、DiffusionGemmaは画像生成AIと同じ「拡散(ディフュージョン)」の仕組みをテキストに応用し、ノイズ状態のトークンを段階的に文章へ磨き上げる方式を採用しています。ローカル実行では従来型モデルの約4倍の生成速度をうたっており、Apache 2.0ライセンスで商用利用も可能です。テキスト生成の基本方式そのものを変える試みとして、AI業界で注目が集まっています。
何が起きたか:ノイズから文章を生成する新方式のオープンモデル
AI専門メディアのThe Decoderが報じたところによると、DiffusionGemmaは256個のランダムなプレースホルダートークンのブロックから開始し、複数回のパス(反復処理)を通じて読める文章になるまで全体を同時に洗練していく、という拡散ベースの生成方式を採用しています。ChatGPTやGeminiなど従来の言語モデルが「次の1語」を順番に予測していくのとは根本的に異なるアプローチです。
モデルの規模は総パラメータ260億(26B)で、MoE(Mixture of Experts)構成により1ステップあたり実際に動くのは38億(3.8B)パラメータに抑えられています。低精度に量子化すればVRAM 18GBに収まるため、ハイエンドのコンシューマー向けGPUでも動作します。
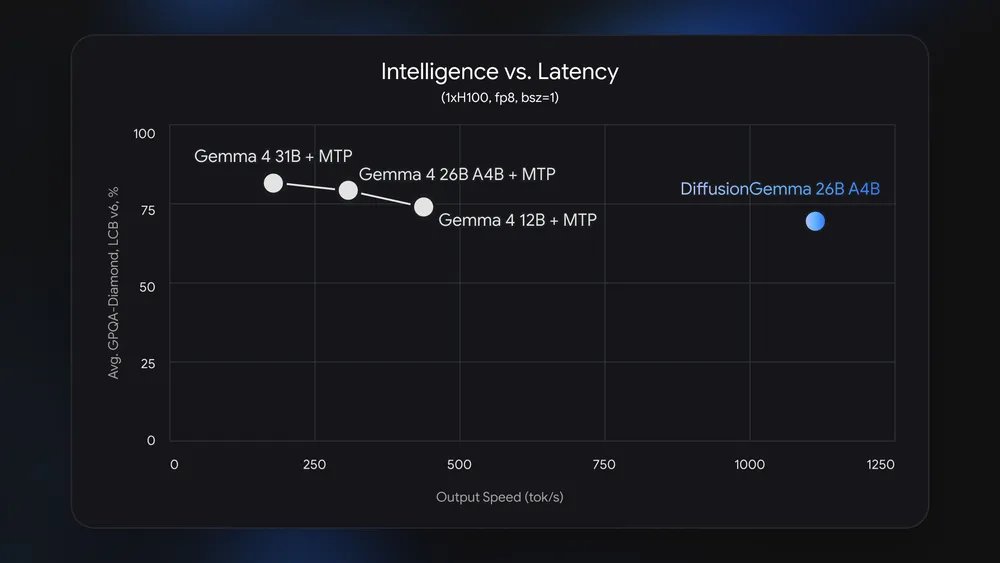
性能面では最適化を担当したNVIDIAが、H100で毎秒約1,000トークン、デスクサイド機のDGX Sparkで毎秒150トークン、DGX Stationで最大毎秒800トークンという数字を公表しています。GeForce RTX 5090では毎秒700トークン超とGoogleは説明しており、ローカルのシングルユーザー利用では専用GPU上で従来型モデルの約4倍の速度で動くとされています。
モデルの重みはHugging FaceでApache 2.0ライセンスのもと公開されており、vLLM、MLX、NVIDIA NIM、Gemini Enterprise Agent PlatformのModel Gardenなどから利用できます。ファインチューニング用にUnslothやNVIDIA NeMo Frameworkが対応済みで、llama.cpp対応も計画されています。Googleは研究者向けにJAXベースのツールキット「Hackable Diffusion」も公開しました。詳細はGoogle公式ブログで確認できます。
なぜ重要か:速度と引き換えに精度は低下、それでも意味がある理由
注意すべきは、DiffusionGemmaが「速いが、賢さでは劣る」モデルだという点です。ベンチマークではMMLU ProやAIME 2026、LiveCodeBench v6、GPQA Diamond、tau2-benchなどの主要指標で、同規模の従来型モデルであるGemma 4 31Bを下回るスコアにとどまっています。最高の回答品質が必要な用途では、引き続き従来型のフラッグシップモデルが優位です。

それでもこのリリースが重要なのは、テキスト生成の「逐次生成」という前提を崩す本格的なオープンモデルを、Googleという大手が量産品質で出してきたことにあります。拡散型は文章全体を同時に編集していくため、文章の途中への挿入、コードの穴埋め、数独のように前後関係を行き来する非線形タスクに強いという特性があります。1トークンずつの生成では原理的に苦手だった処理に、別の選択肢が生まれたことになります。
また、毎秒1,000トークン級の生成速度は、応答の体感待ち時間がほぼゼロに近づくことを意味します。リアルタイム性が求められる対話UIや、大量のテキストを高速に下処理するパイプラインでは、多少の精度低下より速度が価値を持つ場面が少なくありません。「用途に応じて生成方式を選ぶ」時代の入り口と言えます。
今後の動き:拡散型LLMの競争と「速さの使いどころ」
今後の注目点は3つあります。第一に、拡散型テキストモデルの競争です。GoogleはGemini系でも拡散型の研究(Gemini Diffusion)を進めてきており、今回のオープンモデル公開で他のAI企業や研究機関の追随が加速する可能性があります。第二に、エコシステムの広がりです。llama.cpp対応が実現すれば、一般的なPCでローカル実行するユーザー層にも一気に普及が進みます。第三に、精度改善のペースです。初代は精度面で従来型に譲りますが、拡散型の改善余地はまだ大きく、次世代で差がどこまで縮まるかが方式の将来を左右します。
なお、日本のEC事業者の実務に今日すぐ影響するニュースではありませんが、商品説明文の大量生成や検索クエリの言い換えのような「速度と量が物を言う」バックエンド処理は、将来この種の高速モデルが担う有力候補です。AIの処理コストと速度の選択肢が増える流れとして、頭の片隅に置いておく価値があります。
まとめ
GoogleのDiffusionGemmaは、ノイズから文章全体を磨き上げる拡散方式で約4倍の生成速度を実現したオープンモデルです。精度では従来型に及ばないものの、Apache 2.0で誰でも使える形で公開された意味は大きく、テキスト生成方式の多様化が始まる転換点として注目しておきたいリリースです。
※うるチカラでは、生成AIの導入支援から運用最適化まで、貴社のEC事業に合わせたカスタマイズ提案を行っています。無料相談(30分)も実施中ですので、お気軽にお問い合わせください。
https://uruchikara.jp/contact/
引用元: The Decoder
【監修】齋藤竹紘(株式会社オルセル代表 / 19年・5,000社のEC支援実績)

株式会社オルセル代表取締役 / うるチカラ編集長。19年・5,000社以上のEC支援実績を持ち、楽天市場・Amazon・Yahoo!ショッピング・Shopify・Shopee越境ECの実装ノウハウを保有。AI×ECに関する書籍を3冊執筆。「現場で使えるAI実装」を一次情報として発信しています。
この記事を読んだ人は、こんな記事も読んでいます