fetch as googleはその重要性にも関わらず、一般的にまだまだ知名度が低いgoogleの無料Sランクツールです。
特にまだトラフィックが50,000pv以下の、立ち上げてまもないWEBサイトにとっては、fetch as googleはSEOにとって必要不可欠のツールです。
fetch as googleの使い方を知っているというだけで、他の多くのWEBサイトよりも相当優位に立てることは間違いありません。
この記事では、fetch as googleの使い方について、わかりやすく解説していきます。
それでは始めましょう!
サーチコンソールが新しくなったことにより、2019年3月28日より本記事でご紹介をしているFetch as Googleが利用できなくなりました。
Fetch as Googleの代わりとして、新しいサーチコンソールにおいては、
「URL検査ツール」
を利用します。使い方については下記のページをお読みください!
1.fetch as googleとは

fetch as googleは、サーチコンソールという、googleの無料ツールの中の1つの機能になります。
サーチコンソールの中でも、fetch as googleは特に重要な機能です。
それでは、fetch as googleは一体どのような機能なのでしょうか。
googleの説明は下記の通りです。
“Fetch as Google ツールを使うと、サイト上で Google が行う URL のクロールまたはレンダリングの方法をテストすることができます。Fetch as Google を使用して Googlebot がサイト上のページにアクセスできるかどうか、ページのレンダリング方法、ページのリソース(画像やスクリプトなど)が Googlebot に対してブロックされているかどうかを確認できます。”
(引用元:サーチコンソールヘルプ)
わかります?
なんだか難しくないですか。
(googleのWEBサイトの説明はいつもそう。。ユーザーのためって言ってるのに。。。)
fetch as googleを簡潔に説明すると、下記の図のようになります!
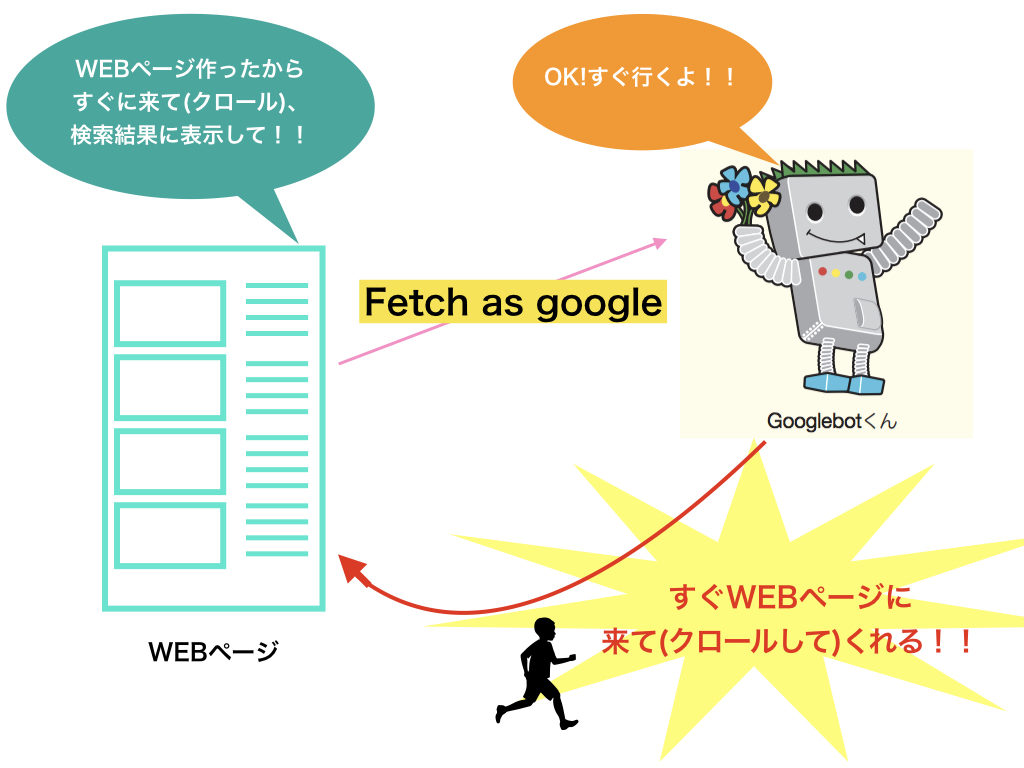
WEBページを作って公開したとしても、Googleの検索ロボット(googlebotくん)が来てくれなければ、WEBページの存在を検索ロボットに知ってもらうことができず、いつまでたっても検索結果に表示されることがありません!
もちろん検索ロボットは世界中のWEBページをパトロールしているので、いつかはWEBページの存在を知り、検索結果に表示されます。
ですが、それを待っていてはいつになったら検索結果に表示されるのかわかりません。
1ヶ月後?
2ヶ月後?
半年後?
もっと長い期間??。。。
1年なんてことはあまりないでしょうが、それでも相当期間検索結果に表示されない、ということは本当によくあります。
それではせっかくWEBページを作っても全く意味がありません。
WEBページを作ったらすぐに検索結果に表示してもらわなければWEBページの目的を達成することができないのは明らかです。
また、検索結果に一度表示されたからと言って、すぐに検索結果で1ページ目に表示される、なんてことはほとんどありません。
検索結果に表示された後、しばらく時間がたってから徐々に検索順位が上がっていき、そして初めてたくさんの人たちに見てもらえる1ページ目に表示される、というのが普通です。
私たちのうるチカラのWEBページも、狙っているキーワードで1ページ目に表示されるためには、検索ロボットがページを見に来てくれてから平均して1ヶ月程度かかります。
だからこそWEBページを作ったらすぐに検索ロボットに見てもらわなければならないのです。
この重要な役割を果たしてくれるのがfetch as googleです。
WEBページのアクセスが増えてくると、呼ばなくても検索ロボットが1日にも何百回も来てくれるようになります。
そのようになった後ではこのfetch as googleは使わなくても良いかもしれません。
ですがそうではないWEBページはfetch as googleは必須ツールです。
冒頭でfetch as googleはSランクツールと言った意味はこのためです。
この重要性にも関わらず、fetch as googleの知名度はとても低いです。
Googleのツールで多くの人が知っているのはアナリティクスだと思います。
ですが、アナリティクスはWEBページを訪問してくれた人を分析するためのツールです。
人がまだ大して来ていないWEBページを分析するよりも、fetch as googleを使って人がくるようなWEBページにすることの方が優先順位は高いはずです。
それにも関わらず知らない、もしくは使い方がわからないという人が多いのはとても残念なことです。
WEB制作会社ですら知らない人たちもいるようで、
「今WEBサイトを作ったばかりなので、検索に引っかかってくるまで3ヶ月から半年かかります。」
などという説明をする会社も少なくないようです。
WEBページを新規作成したらfetch as googleをする。
WEBページを更新してもfetch as gooleで検索ロボットに来てもらう。
ということを必ず徹底していただきたいと思います。
2.fetch as googleのもう1つの使い方

これまで説明してきた通り、fetch as googleの最も重要な使い方は、検索ロボットに来てもらうということです。
これによって、ロボットが来てくれるのをひたすら待つのではなく、自分から呼ぶことで検索結果に表示されるまでの時間を大幅に短縮することができます。
検索結果に表示されるまでの期間は、私たちの経験によると早ければfetch as googleを使ったと同時に(早ければというかこの場合が多いです)、遅くとも30分以内には検索結果に表示されます。
繰り返しになりますが、これを知らない人が多いのが本当に不思議です。
また他にもfetch as googleは「レンダリング」という機能があります。
レンダリングというとまた何だか難しそうですが、
検索ロボット(googlebotくん)と人それぞれがWEBページをどのように見ているのか
ということがわかる機能です。
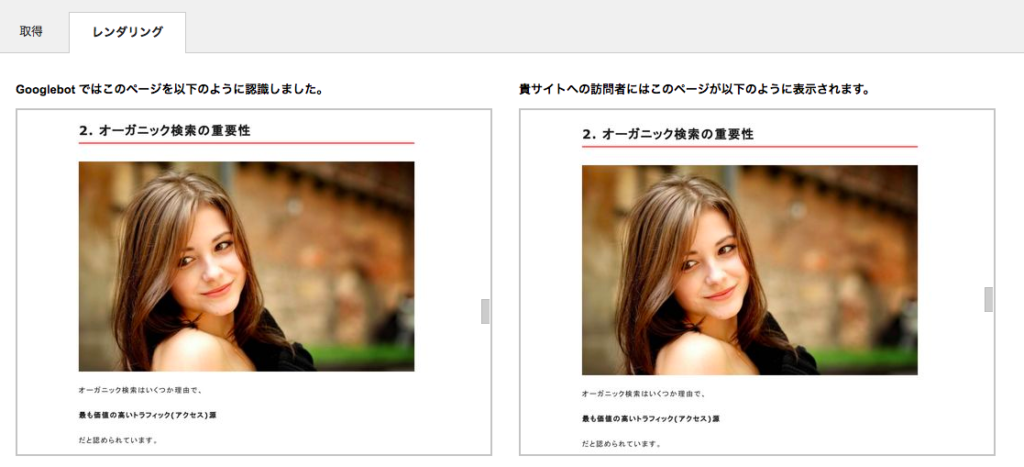
ほとんど同じように見えるのが通常ですが、もしおかしな表示になっている場合にはhtmlやその他コーディング上の問題があります。
fetch as googleはPC・スマートフォンそれぞれについて確認・クロールすることができるので、WEBサイトがモバイルフレンドリーになっているのかを確認する際にも使うことができます。
3.Fetch as googleを使う5つの場面

それではこれまでのまとめも兼ねて、fetch as googleを使う5つの場面についてまとめておきます。
1)サイトを立ち上げたとき、クローラーにサイトの存在を知らせてインデックスしてもらう
サイトを立ち上げたあとしばらく日が経ち、かつ頻繁に更新を行うことで、Googleが「このサイトは定期的にクロールしないと!」と思ってくれれば、定期的にクロールしてくれるようになりますが、特に新しいサイトにはなかなかクローラーが回って来てくれません。
すなわち、インデックスされずに検索結果の表示対象にもなっていないかも!?
そんなことにならないためにも、立ち上げたらまず「サイトできたよ!Googleさん来て!」と呼び込んでおくことで、早くインデックスされるようになります。
2)ページを更新したことをクローラーに知らせてインデックスしてもらう
新しくページ作成したとき、サイトを更新したときにも使うといいでしょう。
「更新したよ!」
とクローラーを呼び込んでおけば、きちんとインデックスしてもらえます。
また、titleやディスクリプションを変更した際にもきちんとGoogleにそれを伝えるべくリクエストしておきましょう。
ちなみに、WEBページを更新することは、WEBページを新しく作成するのと同じかそれ以上にSEO的によい効果があります。
本サイト「うるチカラ」でも、記事をバージョンアップしてfetch as googleを使うと、早いと2日程度で検索順位が大きく飛躍するため、定期的なバージョンアップを行なっています。
3)スマホから正しく見えているか確認できる
レンダリングの説明でも触れましたが、クローラーには2種類あり、PCのクローラーとは別に、モバイルのクローラーがあります。
fetch as googleでは、クローラーの種類を選ぶことができるため、モバイルからきちんと見えているかを確認することが可能なのです。
4)自分のサイトをクローラーがどう認識しているか確認できる
「なかなか検索結果に出てこないけど、ちゃんとGoogleに認識してもらっているだろうか…。」
そんな風に心配になったときにも使えます。
レンダリング機能です。
クローラーがサイトをちゃんと読み取れているか、どのように読み取られているかをチェックすることができるのです。(例えば「ページがない」「クロール対象になっていない」と認識されている場合が考えられます)
きちんとクローニングされているかわからなければ、クローラーにリクエストを送る必要があるのかもわかりませんよね。なので、なんとなく不安になったり、何かおかしい気がする…と思ったら、fetch as googleを利用してみるといいでしょう。
5.リダイレクト状況が確認できる
リダイレクトとは、Aというページにアクセスした時にBというページに移転するように設定するWEBページの施策のことです。
一番有名なのが、新しいWEBサイトを立ち上げた際に、古いWEBサイトのURLにアクセスしてきた訪問者を永続的に強制的に転送する、「301リダイレクト」というものです。
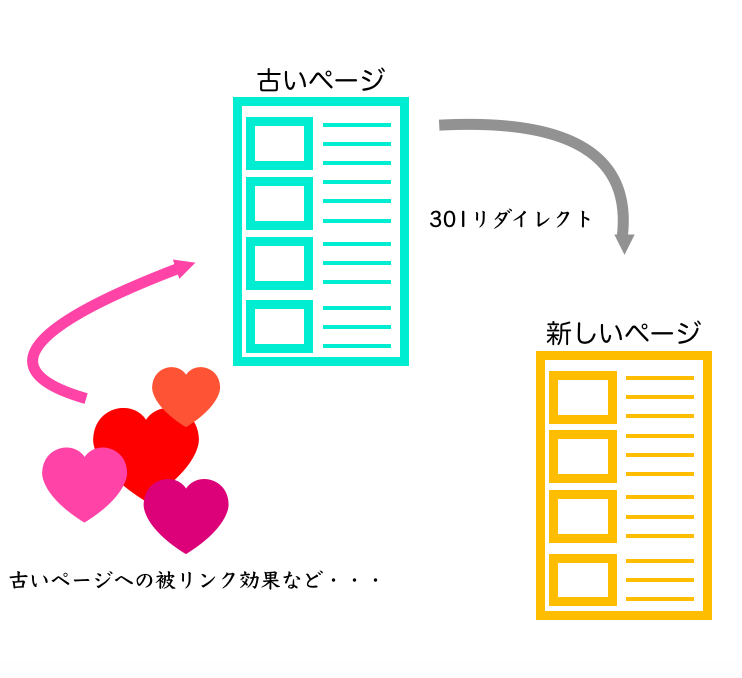
ページの移転などに伴ってリダイレクト設定したときは、正しく設定されているか確認しておきましょう。
間違ったページにリダイレクトされていないか、などエラーを確認することもできます。
4.fetch as googleの使い方

それでは以下、fetch as googleの具体的な使い方について解説していきます。
ステップ1|サーチコンソールにログインする
冒頭で述べたとおり、fetch as googleはGoogleサーチコンソールの機能のひとつです。
ということで、まずはサーチコンソールにアクセスし、<今すぐ開始> からログインします。

ログインしたら、複数サイトを運営されている場合は、今回クロールを依頼したいサイトのプロパティをクリックします。
ステップ2|fetch as googleにアクセスする
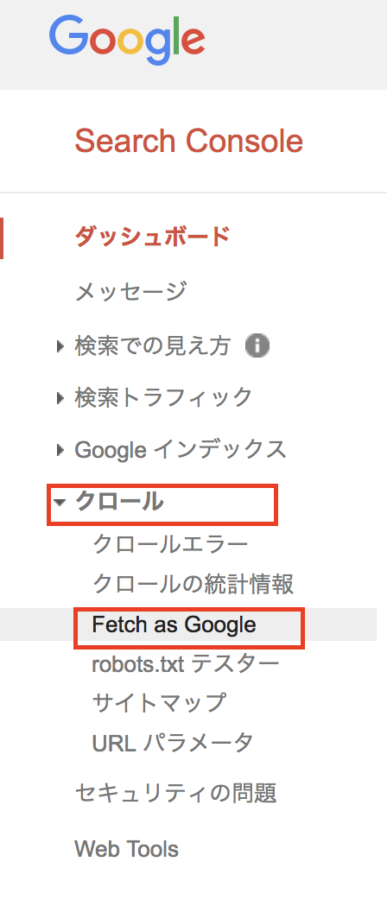
左サイドメニューから
<クロール > → <fetch as google> を選択し、クリックします。
※最近、サーチコンソールの管理画面がリニューアルされ、アナリティクスのように見やすいものになりました。
ですが、現在のところ、fetch as googleを行う場合は、旧バージョンに戻す必要があります。
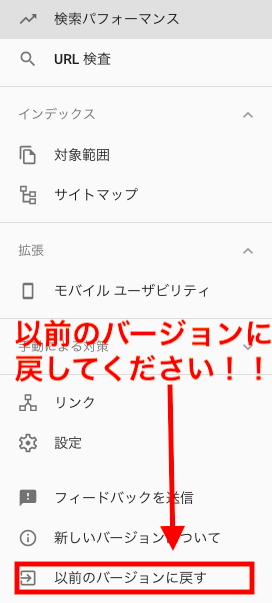
新しい管理画面になってしまっている場合には、レフトナビの
「以前のバージョンに戻す」
をクリックしてから作業してください。
ステップ3|URLを指定する
クロールをリクエストしたいサイトのURLを指定します。

- ブログを更新した場合 → 更新したページのURL
- リダイレクト設定した場合 →リダイレクト設定したページのURL
- きちんとクロールされているか確認したいページのURL
など、を入力します。
なお、サイト全体(トップページなど)をクロールしてほしい場合には入力欄を空欄のままにしておきます。
もしエラーになってしまう場合には、URLの後ろに「/」の入れていないために起きていることが多いです。
エラーになったら「/」の入力の有無を確認してください。
ステップ4|検索エンジン(Googlebot)の種類を選択する
次に、クロールを依頼する検索エンジンの種類を選択します。

- PC :デスクトップPCを対象としたクローラーからの見え方を確認する場合
- モバイル : スマートフォン:スマホのクローラーからの見え方を確認する場合
(※以前まであった「モバイル:XHTML/WML」「モバイル:cHTML:XHTML/WML」というフィーチャーフォン(ガラケー)向けの選択肢はなくなりました)
用途に合わせ、いずれかを選択してください。
どちらを使って良いのかわからない場合には、若干面倒ですが、
PC・モバイル両方とも
fetch as googleを行なってください。
ステップ5|データの取得とレンダリング
検索エンジンの種類を選択したら、<取得>または<取得とレンダリング>を行います。

単にインデックスのリクエストを送るだけであれば <取得> で十分なのですが、特にはじめのうちはレンダリングを同時に行い、
PC・モバイル共に、Googleに正しくサイトを認識されているか確認しておくことをおすすめします。
人の目ではブラウザ上できちんと表示されていても、クローラーには正しくは見えていない可能性があるのです。レンダリングチェックすることで、クローラーがどのようにページを認識しているかを確認することができます。
<取得してレンダリング>をクリックしたらデータ取得完了までしばし待ちましょう。少し時間がかかります。
長いと1、2分、場合によってはもっとかかる場合もあります。
完了しなくても焦らずに待ってください。
データの取得が完了すると、ステータスが表示されます。
| ステータス | 内容 |
|---|---|
| 完了 | 正常にページのクロールが完了しました。 |
| リダイレクトされました | サーバー側でリダイレクト設定がされている、 もしくはURLの入力ミスの可能性があります。 |
| 見つかりませんでした | ページが見つからない(404コード)と表示されている可能性があります。 |
| 権限がありません | サーバー側で閲覧禁止(403エラー)されている もしくはGoogleからのアクセスをブロックしている可能性があります。 |
| DNS で検出されません | GoogleがURLを取得できませんでした。URLを確認してください。 |
| ブロック | robots.txt ファイルによりアクセス制限されています。 robots.txt を更新しましょう。 |
| robots.txt に アクセスできません |
robots.txt ファイルにアクセスできなかったため、 サイトをクロールすることが できませんでした。 クローラーがアクセスできるようrobots.txt を作成しましょう。 |
| アクセスできません | サーバーやアクセス状況を確認しましょう。 |
| 一時的にアクセスできません | 応答に時間がかかり過ぎた、もしくはリクエストが多すぎる可能性があります。 しばらく経ってから再度、取得してみましょう。 |
| エラー | 取得が完了できませんでした。再度、取得してみましょう。 |
問題なく取得されれば、通常<完了>と表示されます。その他ステータスの表示は以下のようなパターンがあります。
「完了」「一部」以外のステータスが表示された場合は、Googleによりページが正しく認識されていません。
Search Console ヘルプ|Fetch as Google の結果を診断する
で該当するステータスを探して調べ、対応しましょう。
ステップ6|リクエストを送信する
正しくデータが取得されれば「インデック登録をリクエスト」というボタンが表示されます。

いよいよ、クロールとインデックスを依頼しますよ!
<インデック登録をリクエスト>をクリックします。
※ちなみにデータの取得から4時間を越えると、無効になってしまうのでご注意ください。
下記のようなポップアップ画面が出てきます。
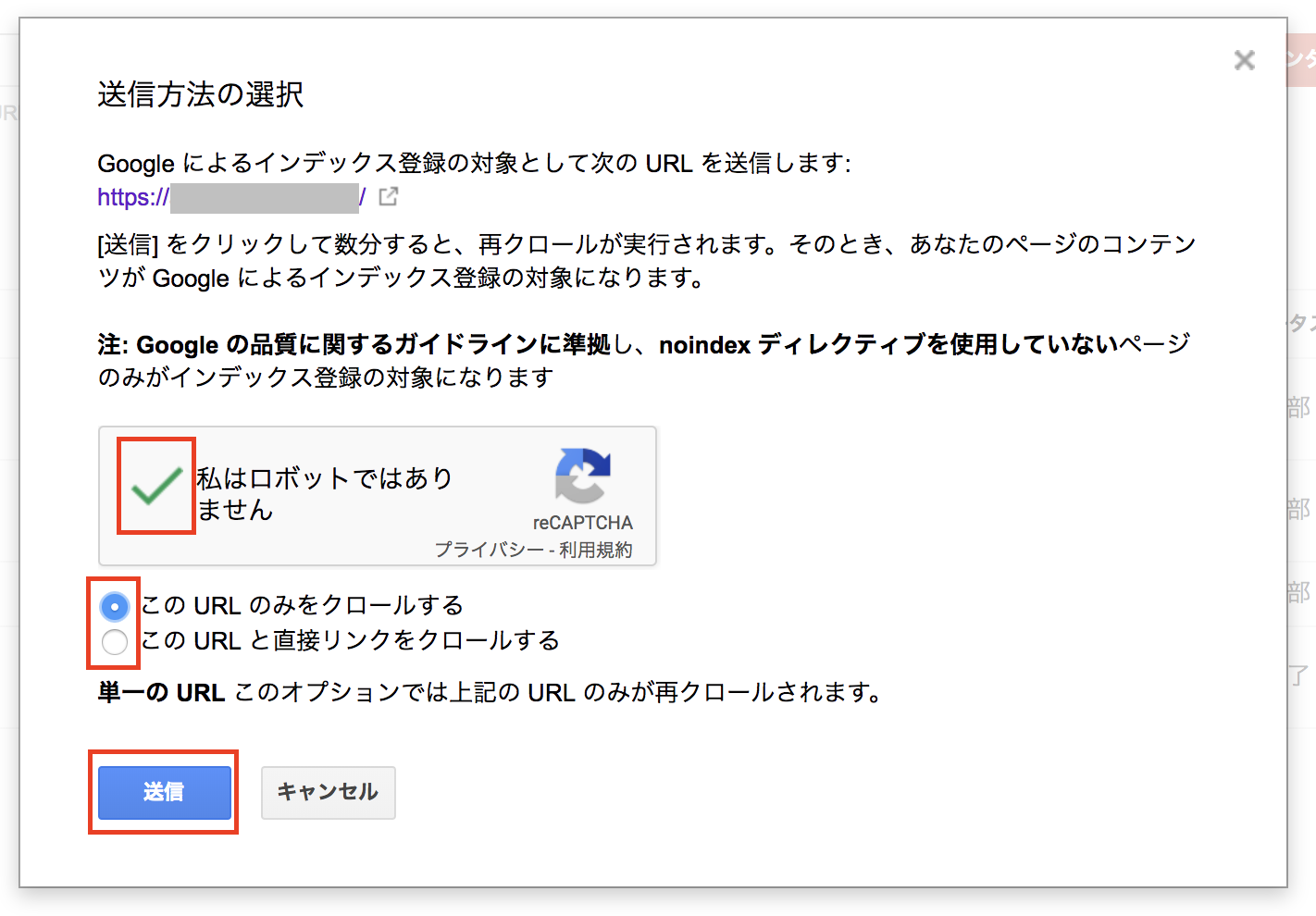
「私はロボットではありません」にチェックをいれたら、インデックス対象を選択します。
●この URL のみをクロールする(個別URL)
クロール対象として 、今回指定した1つのURLだけリクエストする場合です。
ページを更新した際や、新しくUPした記事などの場合は基本こちらでOKです。
●この URL と直接リンクをクロールする(全URL)
指定したURLとそのページ上に掲載される全てのリンクを対象にクロールをリクエストとする場合です。
通常はトップページなどで使用します。
最後に<送信>ボタンを押します。
「インデックス登録をリクエスト済み」となれば完了です。

特にはじめのうちは
更新 → fetch as google! というクセをつけておくといいでしょう。
【補足①】正しくインデックスされたか確認してみよう
念のため、きちんとインデックスされたか確認しておきましょう。
WEBページがインデックスされているのかどうかというこの方法は必ず覚えてください。
まず、ブラウザを開いきます。Google ChromeでもInternet Explorerでも、新しいタブでも既存のタブでも何でもかまいません。
上のURL欄に直接「site:」と入力し、
確認したいURLをその後ろに入力します。
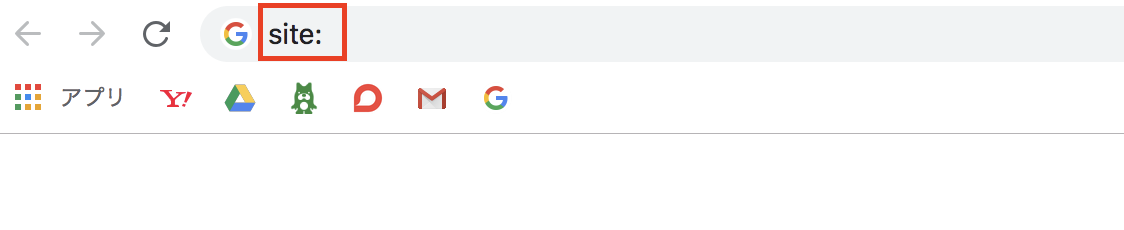
「site:」と打ち込み

その後ろにリクエストしたURLを入力。キーボードの<Enter>キーを押します。
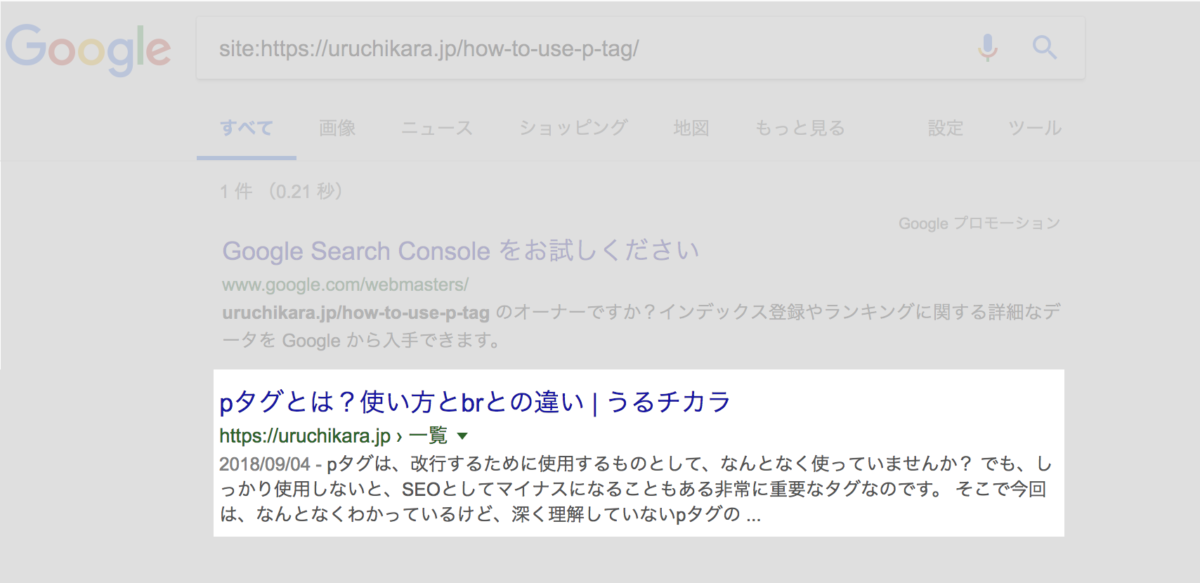
検索結果に指定のサイトが表示されればOKです。きちんとインデックスされています。
ちなみにインデックスされいない場合は
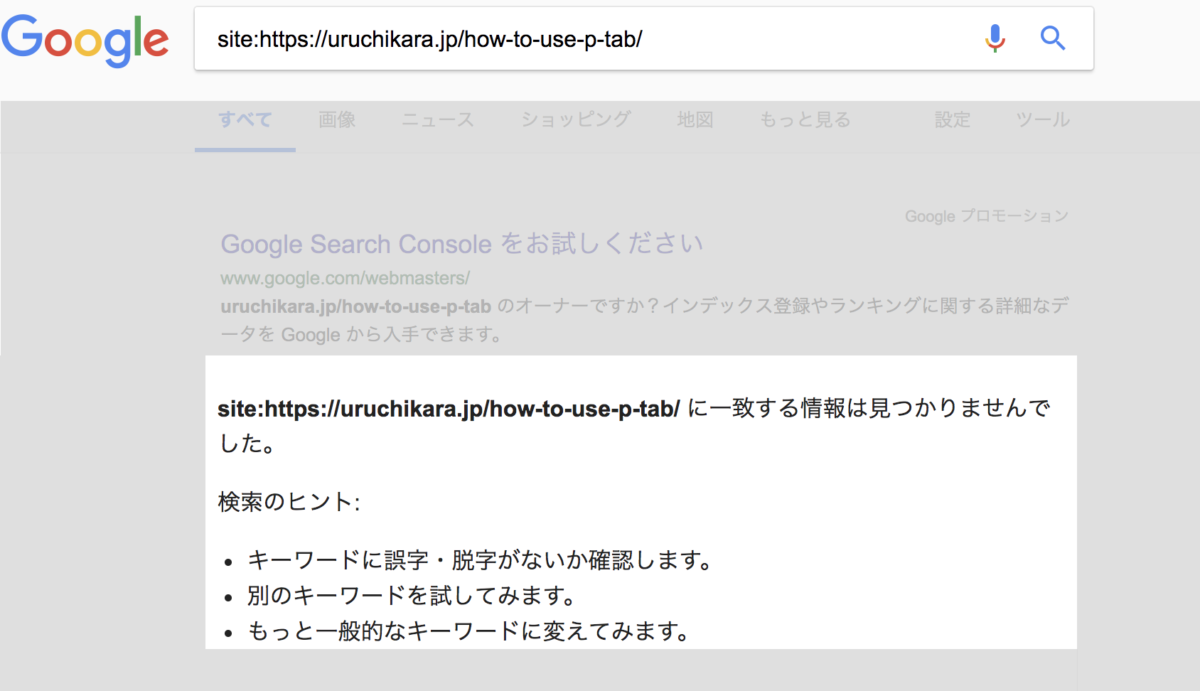
「一致する情報が見つかりませんでした」と表示されますので、URLを確認しやり直しましょう。
【補足②】レンダリングチェック
レンダリングの詳細を見てみましょう。

「レンダリングリクエスト」のついている結果の行をクリックします。すると、レンダリングの詳細が表示されます。
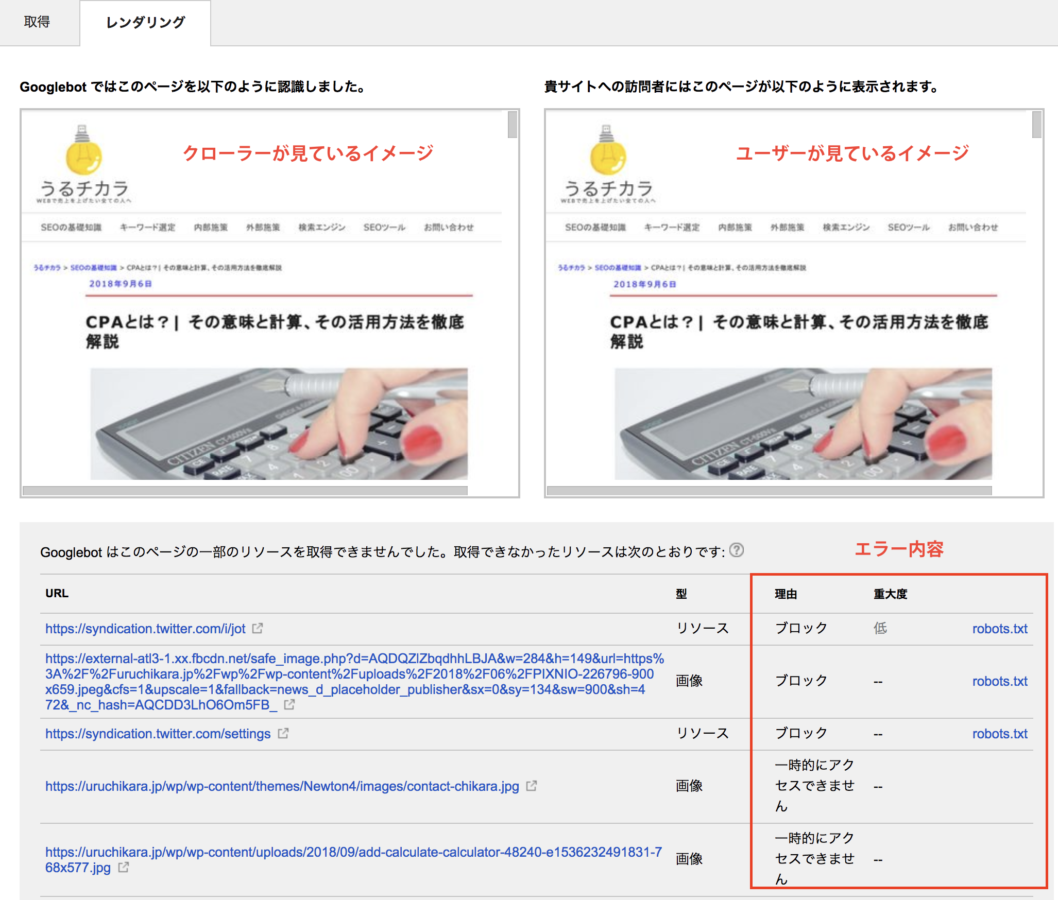
何かしらエラーがある場合には、その理由も示されるので、先ほどの表を参考に対処しましょう。
また同じページでもクローラー(Googlebot)の種類によっても内容が異なります。同じページをモバイルタイプで見た結果はこちらです。

どちらもチェックし、適切に対応しておきましょう。
デスクトップ用のブラウザでは問題なく表示されていても、スマートフォンでちゃんと表示されていないことがあります。レスポンシブデザインのサイトではチェックツールとして改善に活用できますよ。
5.fetch as googleの回数制限
fetch as googleは無制限に使えるわけではありません。
1日あたりの使用回数に制限があります。
●この URL のみをクロールする(個別URL)は、1日10回まで
●この URL と直接リンクをクロールする(全URL)は1日2回まで
回数制限があることは覚えておいてください。
また、この回数は変更になる場合がありますので、注意してください。
6.まとめ
いかがでしたでしょうか。
Googleには、知らないともったいない機能がたくさんあります。
サーチコンソール、アナリティクスを最大限活用してサイト改善につなげてください。

齋藤 竹紘(さいとう・たけひろ)
株式会社オルセル 代表取締役 / 「うるチカラ」編集長
Experience|実務経験
2007年の株式会社オルセル創業から 17 年間で、EC・Web 領域の課題解決を
4,500 社以上 に提供。立ち上げから日本トップクラスのEC事業の売上向上に携わり、
“売る力” を磨いてきた現場型コンサルタント。
Expertise|専門性
技術評論社刊『今すぐ使えるかんたん Shopify ネットショップ作成入門』(共著、2022 年)ほか、
AI × EC の実践知を解説する書籍・講演多数。gihyo.jp
Authoritativeness|権威性
自社運営メディア
「うるチカラ」で AI 活用や EC 成長戦略を発信し、業界の最前線をリード。
運営会社は EC 総合ソリューション企業株式会社オルセル。
Trustworthiness|信頼性
東京都千代田区飯田橋本社。公式サイト alsel.co.jp および uruchikara.jp にて
実績・事例を公開。お問い合わせは
info@alsel.co.jp まで。
この記事を読んだ人は、こんな記事も読んでいます