AIコーディングエージェントの「弱点」を可視化する研究結果が公表されました。上海交通大学が主導した国際研究チームが新ベンチマーク「SWE-Explore」で複数のエージェントを評価したところ、修正すべきファイルまではほぼ正しくたどり着く一方、実際に直すべき行レベルになると精度が急落し、重要な行の14〜19%しかカバーできていないことが分かりました。自社ECサイトやShopifyアプリ、楽天・Amazon連携ツールの開発をAIに任せ始めた日本のEC事業者にとって、品質管理の勘所を示す結果です。
何が分かったのか:ファイルは当てても「行」で外す
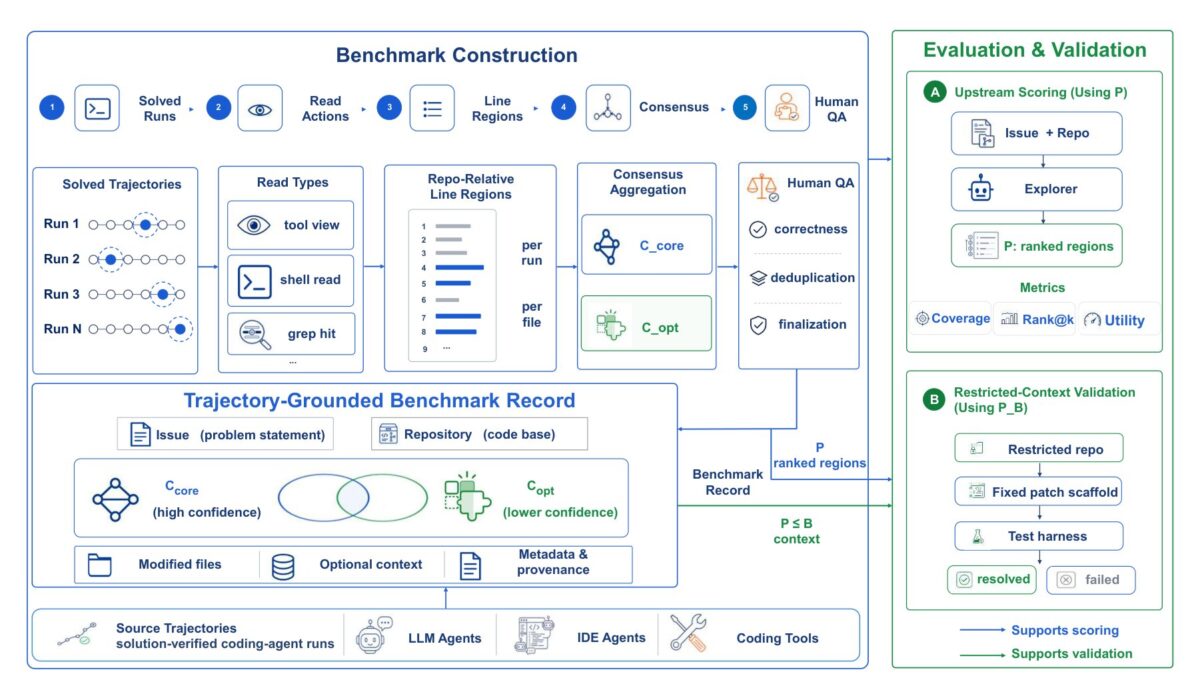
この研究はThe Decoderが報じたもので、10言語・848問(うちPythonが547問)からなるデータセットで、コード修正に必要な「核心部分」をエージェントがどれだけ正確に特定できるかを測っています。
評価対象には、Claude Code、Codex、OpenHands、AutoCodeRoverなどのエージェントと、GPT-5.4、Gemini 3 Pro、Claude Sonnet 4.6、Kimi K2.6といった言語モデルが含まれます。結果として、ファイル単位では適切な対象を探し当てるものの、行レベルの精度は大きく落ち込み、一般的なエージェントが押さえられた重要行は全体の14〜19%にとどまりました。単純なキーワード検索に至っては「ほぼ偶然と変わらない」水準だったとされています。
研究チームは、バグ修正を成功させるには必要な核心部分の50〜75%以上が見えている必要があると指摘しています。つまり、現状のエージェントが見せてくる「直すべき箇所」は、修正を完遂するのに必要な情報量に届いていないケースが多いということです。
なぜEC事業者に関係するのか
EC事業者の現場でも、商品ページのカスタマイズ、定期購入ロジックの修正、在庫連携バッチの不具合対応などをAIコーディングエージェントに頼む場面が増えています。今回の研究が示すのは、AIが「このファイルのこのあたりですね」と自信ありげに直してきても、本当に直すべき行を取りこぼしている可能性があるという事実です。
特に決済・在庫・受注のように、1行の見落としが売上や顧客対応に直結する領域では、エージェントの提案を鵜呑みにするのは危険です。表面的にエラーが消えても、関連する別の行が未修正のまま残り、セール当日に在庫数がずれる、クーポンが二重適用される、といった事故につながりかねません。
逆に言えば、AIに「全体のどこを直すべきか」を網羅的に把握させる前提を整えれば、生産性は大きく上がります。研究が示す50〜75%という閾値は、人間側が修正範囲の文脈をどれだけAIに渡せているかを点検する目安になります。
今後の動きと現場での向き合い方
エージェントの精度は今後も改善が進む見込みですが、当面は人間によるレビュー前提で使うのが現実的です。EC開発の現場では、第一にAIの修正提案を受け取ったら「直したファイル以外に同じ変更が必要な箇所はないか」を必ず問い直すこと、第二に決済・在庫・受注まわりの修正は本番反映前にステージング環境で再現テストを通すこと、第三に修正の意図と影響範囲をAIに日本語で説明させ、漏れがないか自分の言葉で確認することが有効です。
SWE-Exploreのような評価軸が広がれば、「どのエージェントが行レベルまで正確か」を比較して選べるようになります。自社の開発体制にAIを組み込む際は、ファイル特定の速さだけでなく、修正の網羅性まで見て判断したいところです。
まとめ
AIコーディングエージェントは正しいファイルにはたどり着くものの、修正すべき行の14〜19%しか押さえられないという研究結果が出ました。EC事業者がAIに開発を任せる際は、特に決済・在庫・受注の修正で「行レベルの取りこぼし」を前提にレビューを組むことが、事故を防ぐ実務的な姿勢になります。
※うるチカラでは、生成AIの導入支援から運用最適化まで、貴社のEC事業に合わせたカスタマイズ提案を行っています。無料相談(30分)も実施中ですので、お気軽にお問い合わせください。
https://uruchikara.jp/contact/
引用元: The Decoder
【監修】齋藤竹紘(株式会社オルセル代表 / 19年・5,000社のEC支援実績)

株式会社オルセル代表取締役 / うるチカラ編集長。19年・5,000社以上のEC支援実績を持ち、楽天市場・Amazon・Yahoo!ショッピング・Shopify・Shopee越境ECの実装ノウハウを保有。AI×ECに関する書籍を3冊執筆。「現場で使えるAI実装」を一次情報として発信しています。
この記事を読んだ人は、こんな記事も読んでいます